Language Navigator
Language Navigator is the open, web-based platform that unifies and visualizes crucial, contextualized data about the world’s languages, their usage, and digital support.

The Definitive, Open Platform for Global Language Data.
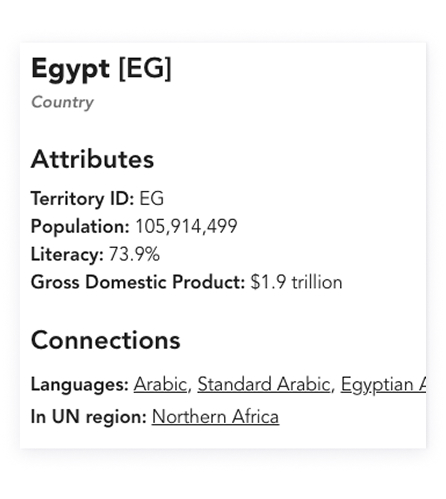
The Language Navigator brings together disparate linguistic metadata, such
as language classification, geographic usage, digital support and writing
systems, into a single, navigable platform. It is designed to reduce the
time, effort, and ambiguity involved in answering key questions about the
world’s languages.
Our Motivation
Transparency and Trust
The goal of Language Navigator is to establish trust and transparency by exposing the origin and reliability of each data point for all languages. We allow users to understand what’s known, what’s debated, and where there are gaps. The platform is free and open-source, ensuring public access and maintainability.
Actionable Intelligence for Decision-Makers
We make complex data interpretable and actionable. By surfacing key indicators, like population size, writing system readiness, and digital presence, the Language Navigator guides strategic decisions in product planning, public services, and research. Users are empowered to prioritize localization efforts, plan public services, or advocate for underrepresented languages.
Empowering Marginalized Languages
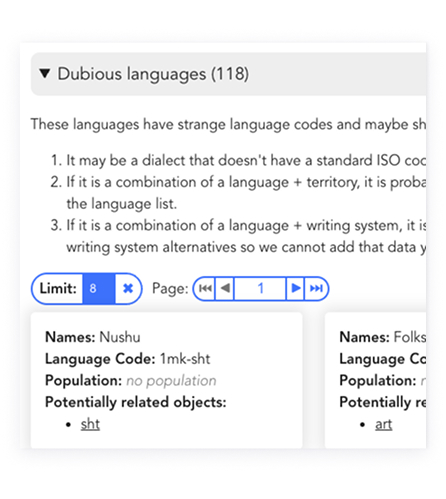
The Language Navigator addresses the problem of linguistic data being fragmented and hard to access, often leading to ambiguous definitions. We are focused on empowering the inclusion of marginalized languages, especially those underrepresented in digital platforms. We highlight presence, needs, and status, and offer multiple standards such as ISO, Glottolog, UNESCO, for context.
How does the Language Navigator work?
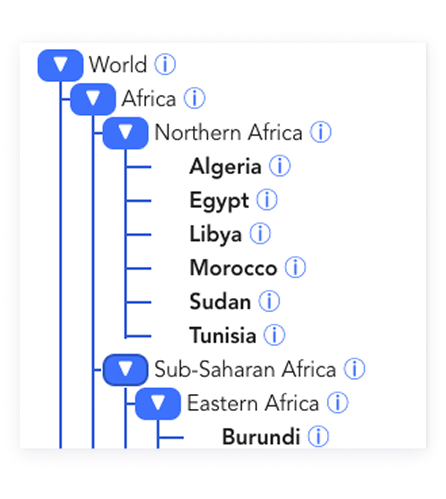
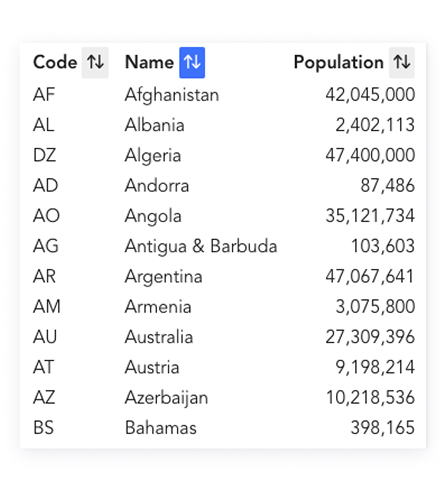
Like many online lists of languages, the Language Navigator catalogs global linguistic data, but stands apart by unifying data from multiple trusted sources (e.g., ISO, Glottolog, UNESCO, CLDR, census datasets). It provides the practical, trustworthy context needed to understand where and how languages are used and how they are (or aren’t) supported digitally.
The Language Navigator supports a wide range of users, including:
- Technology Developers & Product Teams who need to identify which languages to localize into and what writing systems to support.
- Policy & Program Managers who require actionable data on speaker populations and diversity to guide strategic planning for public services.
- Indigenous Language Communities & Advocates who seek insights into representation, localization support, and opportunities for revitalization.
- Researchers & Academics who require transparency in sourcing and the ability to cross-reference different classification schemes.
The platform offers structured navigation, powerful filters, and clear source attribution to make complex data interpretable and actionable for non-technical advocates and experienced researchers alike.
Get Started
Choose from these common objectives to begin exploring:
Contributors
The Language Navigator is a project by the Translation Commons team, spearheaded by Conrad Nied. It is developed and maintained by dedicated volunteers passionate about language and technology.
Data Sources
Our data is sourced from various linguistic databases including:
- Unicode, ISO: Standard language codes and locale data
- Glottolog – Comprehensive language catalog and taxonomy
- UNESCO – Language vitality and cultural data
- Government censuses and academic papers
- And many other sources